Josh's Note — Verilog
Part 2 Verilog 语言基础
1. 两种设计方法(Top-Down 和 Bottom-Up)
在传统意义上,设计硬件电路主要是使用自底向上(Bottom-Up)的设计方法。工程师们总是从最底层的逻辑门开始,逐渐搭建成较大的模块,然后再将这些模块组成更大的模块,最后形成整个设计。
在 Part 1——初识 HDL 设计方法中已经提到,随着 HDL 和逻辑综合技术的进步,工程师们逐渐可以使用自顶向下(Top-Down)的方法来设计硬件。这样,工程师们首先关注于设计的规格(Specification),然后将规格分解为一个个模块,再分解为更小的模块。然后采用 HDL 的可综合子集直接描述硬件的行为,由逻辑综合工具自动完成由 HDL 到门级电路的转换。
最近几年,随着 IP 核市场的逐渐兴起,许多设计者逐渐意识到利用现有的 IP 核可以帮助节约设计成本、减少设计周期,有许多设计工程师,甚至希望所有的设计模块都使用现成的模块,自己仅仅开发一些简单的粘合逻辑。这就有点像电路板设计的过程,工程师将各种芯片集成到一块电路板上,自己完成这些芯片间的互连和一些简单的 CPLD 逻辑设计,以及对微处理器的编程。使用现有的 IP 来搭建系统实际上也是一种自底向上(Bottom-Up)的设计方法。
从以上描述可以看出,设计硬件电路时,这两种设计方法都有可能采用。Verilog HDL 可以完全支持这两种设计方法。
- 在门级的设计中,用户可以直接实例化 Verilog 语言中的门级原语构建系统;
- 如果需要描述硬件的行为,可以使用 Verilog 的行为级描述功能;
- 如果要使用 IP 核,只要在设计中直接实例化 IP 核即可。
EDA 行业的先行者们发明了 Verilog 硬件描述语言,其最根本的目的就是用 Verilog 来描述硬件的行为,但是有的描述是不需要实现为硬件电路的。
如果用户的 Verilog 描述的最终目的是要实现为硬件电路,那么要时刻提醒自己是在设计电路,这与用 C 语言对处理器编程有很大的区别。
硬件电路最大的特点是由一个个模块组成,模块之间使用互连线,各个模块独立并行工作。同时,它们通过输入和输出端口与相邻的模块互相沟通。每个硬件单元都有相应的延时特性,硬件的延时也是设计的目标之一。
2. 从 Verilog 实例出发
2.1. Verilog 实例
首先看一个简单的如图 2-1 所示的电路(模块):HelloVlog。它可以是一个独立的设计,也可以是更大的系统的一个组成部分。
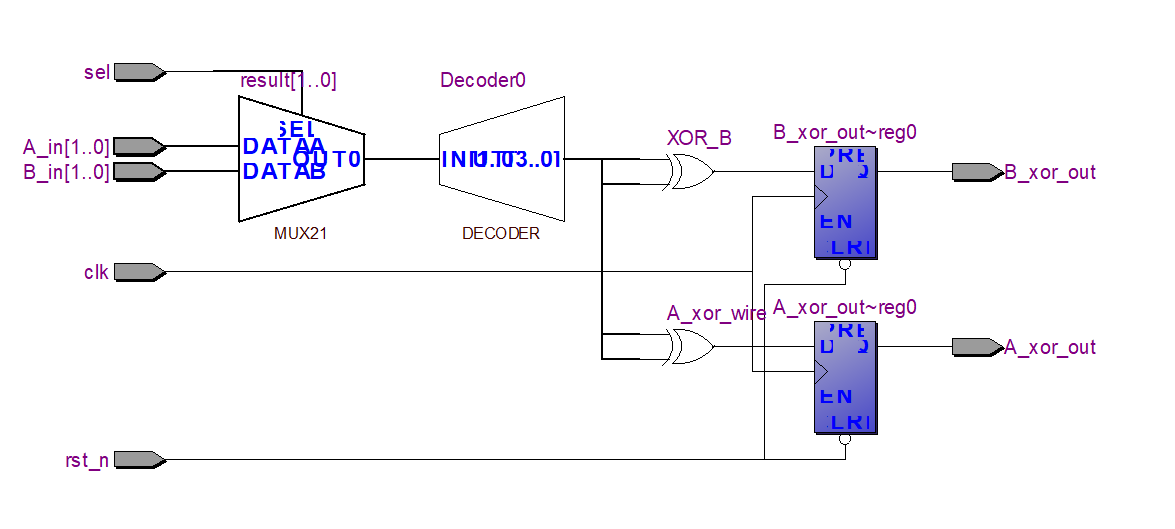
该电路首先在两个 2 位的输入数据 A_in[1:0] 的和 B_in[1:0] 之间,由 sel 信号做二选一。后面是一个 2-4 译码电路,将输入的信号 result[1:0]解析成 eq0、eql、eq2 和 eq3 这4个信号,它们同时只有一个为 1。
将 eq0 和 eql 相异或(xor),eq2 和 eq3 相异或。然后,将两个异或的结果 A_xor_wire 和 XOR_B 分别寄存输出给 A_xor_out 和 B_xor_out。两个输出寄存器带有低有效(active low)的异步复位端。
这些电路单元都是同时并行工作的,相互之间并没有先后顺序关系,这一点与软件设计程序很不一样。
下面具体分析 HelloVlog 模块 的电路功能,代码如下。
1 | // 编译指令, 定义时间单位和时间精度 |
代码分析如下。
二选一多路选择器
对于
MUX21这样二选一的电路,将采用如下的数据流描述(assign语句):HelloVlog.v 1
assign #3 result = sel ? B_in : A_in;
assign是 Verilog 中的关键词,用它赋值的语言称为连续赋值语句。如果
sel为真(1),则选择B_in,否则将选择A_in,而#3表示经过 3 个延时单位,再将选择结果赋值给result,这也模拟了组合逻辑的延时。由于在代码最开头已经使用 Verilog 的编译指令将延时单位定义为 1ns(timescale 1ns/100ps),因此这里的#3代表 3ns 的延时。2 - 4 译码器
关于实现 2 - 4 译码器,则采用了如下的描述:
HelloVlog.v 1
2
3
4
5
6
7
8
9
10always @(result) begin
case(result)
2'b00: begin
{eq3, eq2, eq1, eq0} = #2 4'b0001;
$display ("At time %t-", $time, "eq0 = 1");
end
// ...
default: ;
endcase
end这里采用了另一种描述方式:用
always语句来描述电路的行为。通过case判断result的值来决定eq0~eq3的值。同样,也采用#2来模拟组合逻辑的延时。always和case也是 Verilog 中的关键词。这样的描述方法称之为行为描述,它侧重于描述电路的行为。HelloVlog.v 1
{eq3, eq2, eq1, eq0} = #2 4'b0001;
该语句表示将
4'b0001赋值给eq3~eq0合并成的 4 位变量。{}是 Verilog 的合并符号。异或门
对于
A_xor_wire和XOR_B的两个完全一样的异或门,也采用了两种不同的描述方式:HelloVlog.v 1
assign #1 A_xor_wire = eq0 ^ eq1;
和
HelloVlog.v 1
xor #1 XOR_B(B_xor_wire, eq2, eq3);
xor是 Verilog 中自带的基本逻辑门原语。这里相当于调用了该xor门。而B_xor_wire、eq2和eq3是代入到xor门中的参数。eq2和eq3是输入,B_xor_wire是输出。这里B_xor_wire是eq2和eq3相异或的结果。在 Verilog 中,将调用其他功能模块(包括 Verilog 的内嵌基本逻辑门)称为“实例化(Instantiate)”。实例化类似于软件设计中的调用,但不能简单理解为软件中的调用。软件调用过程是顺序执行的,而实例化的硬件电路在设计中是独立于其他功能块,并行运行的。
这种在模块中实例化其他功能模块的描述方式被称之为结构化描述。
2.2. 3 种描述方法
从以上的描述可以看出 Verilog 语言的 3 种基本的描述方法(基本上所有的 Verilog 功能模块都是由这 3 种方式来描述):
数据流描述:采用
assign语句,该语句被称为连续赋值语句;行为描述:使用
always或initial语句块,其中出现的语句被称为过程赋值语句;结构化描述:实例化已有的功能模块。结构化描述主要有以下 3 种:
Module 实例化:实例化已有的 module;
门实例化:实例化基本的门电路原语;
用户定义原语(UDP)实例化:实例化用户定义的原语。
在 Part 3——描述方式和设计层次中会详细介绍 Verilog 语言中的这 3 种描述方式。
3. Verilog 的基本词法
Verilog HDL 是一种大小写敏感的语言,这一点与 VHDL 不同,因此在书写的时候要格外注意。在 Verilog 语言中,所有的关键字(又叫保留字)都为小写。Verilog 的内部信号名(或称为标识符)使用大写和小写都可以。标识符可以是字母、数字、
$(美元符号)和_(下划线)任意组合,只要第一个字符是字母或者下划线即可。因为 Verilog HDL 对大小写敏感,因此养成良好的信号定义习惯非常重要,否则容易因为大小写不同造成信号的歧义。推荐的信号定义习惯为:所有信号和网线名均小写,用下划线分割单词,而宏变量全部用大写字母。
在上述代码中,用双反斜线
//表示注释。另外,还有一种注释方式,用/* ...... */来表示。所不同的是前者为单行注释,而后者将/*和*/之间的内容全部看作注释内容。通常,注释的内容只是作者为了增强代码的可读性而增加的内容,对整个代码的功能没有任何影响。不过,在一些工具中,尤其是逻辑综合工具,定义了一些特殊的指令,用于控制工具编译过程。这些指令也是以注释的方式出现的。例如:
1
module bl_box(out, data, clk) /* synthesis syn_black_box */;
在
module bl_box的声明处有一行注释,用/* ...... */表示。它看起来是一个注释,实际上,是综合工具 Synplify 中的一个指令,指示 Synplify 将该模块看作一个黑盒(black_box),不处理模块内部的描述。在 Verilog 中,通常使用空格符、跳格符和换行符作为间隔。在书写代码的时候,适当运用间隔符可以提高代码的可读性。比如在声明 4 个
reg型数据eq0~eq3时,可以采用上述例子中的方法:HelloVlog.v 1
reg eq0, eq1, eq2, eq3;
也可以用换行符将其分开:
1
2
3
4reg eq0;
reg eq1;
reg eq2;
reg eq3;在verilog中,还有一些转义字符。比如
\n表示换行符;\t表示 Tab 键;防止引起歧义,就用\表示\符号本身等等。这里不再对 Verilog 的词法做过多的描述,更多可以参考 Verilog IEEE 国际标准(IEEE Std. 1364-2005)。
4. 模块和端口
大型设计往往是由一个个模块构成的。实际上,模块可大可小,大到一个复杂的微处理器系统,小到一个基本的晶体管,都可以作为一个模块来设计。例如,在上述代码中描述的 HelloVlog 就是一个模块。
在 Verilog 中,模块(module)是基本的组成单位。
通常,建议在一个 Verilog 文件中,只放一个 module 定义,而且使文件名称和 module 名称一致。这是一个良好的设计习惯。
以下是 Verilog 中 module 的基本语法:
1 | module 模块名称( 端口列表 ); |
首先,需要有一个名称来标识这个 module。
通常 module 具有输入和输出端口,在 module 名称后面的括号中列出所有的输入、输出和双向的端口名称。
有些 module 也不包含端口。例如,在仿真平台的顶层模块中,其内部已经实例化了所有的设计模块和激励模块,是一个封闭的系统,没有输入和输出。一般这种没有端口的模块都是用于仿真的,不用作实际电路。
在 module 内部的声明部分,需要声明端口的方向(input, output 和 inout)和位宽。按照 Verilog 的习惯,高位写在左边,低位写在右边。比如
1 | input [1:0] A_in; |
就表示两位的总线。
模块内部使用的 reg(寄存器类型的一种)、wire(线网类型的一种)、参数、函数以及任务等,都将在 module 中声明。
一般来说,module 的
input默认定义为wire类型;output信号可以是wire,也可以是reg类型(如果在always或initial语句块中被赋值);inout是双向信号,一般将其设为tri类型,表示其有多个驱动源,如无驱动时为三态。
虽然变量声明只要出现在使用的相应语句之间即可,但还是建议将所有的声明放在所有的语句之前,这样具有较好的可读性。在声明之后,就应该是语句了。语句有如下几种:
initial语句;always语句;- 其他子
module实例化; - 门实例化;
- 用户定义原语(User-Defined Primitive, UDP)实例化;
- 连续赋值(Continuous assignment)。
Verilog 中所有的功能描述都是通过以上几种描述方式进行的。
需要格外注意的是,以上几种语句如果出现在同一个 module 内,其相互之间是没有任何顺序关系的,它们在 module 中出现顺序的改变不会改变 module 的功能,这正是硬件的一大特点。有硬件电路原理图设计经验的读者们可以想象一下画原理图的过程,先画哪个,后画哪个器件根本没有任何关系。在 Verilog 中也是类似的道理。
5. 编译指令
在 Verilog 语言中,提供了一些编译指令,用于指导编译器的工作。例如,定义宏、文件包含、条件编译、时间单位和精度定义等。
Verilog 中的编译指令是从 C 语言中的“预处理指令”演变得来的。这里列出了一些常用的编译指令如下:
`timescale;`define, `undef;`ifdef, `else, `endif;`include;`resetall。
与 C 语言中使用的 # 不同,Verilog 中使用反引号“`”来标识编译指令。编译器一旦遇到某个编译指令,则其在整个编译过程中有效,可以包含多个文件,直到编译器遇到另一个相同的编译指令。
5.1. `timescale
在每一个 module 文件前面加上 ` 的编译指令,就可以保证该文件中的延时信息受其自身文件中的 `timescale 编译指令指导。否则在编译过程中,该模块将沿用上一个 `timescale 的值,或者使用缺省值。
在上述实例代码描述的 HelloVlog 模块中使用了一个`timescale 1ns/100ps 编译指令。其中 1ns 表示延时单位,100ps 表示时间精度,也就是编译器所能接收的最小仿真时间粒度。`timescale 编译指令在模块外部出现,并且影响后面模块中所有的时延值,直到遇到下一个 `timescale 或 `resetall 指令。
比如语句:
1 | assign #(1.16) A_xor_wire = eq0 ^ eq1; |
如果采用 `timescale 1ns/100ps 编译指令由于延时单位是 1ns,同时最小时间粒度是 100ps,即 0.1ns ,那么根据四舍五入的规则,1.16ns 则实际上对应 1.2ns 延时。如果采用 `timescale 1ns/10ps 编译指令,由于延时单位是 1ns,同时最小时间粒度是 10ps,即 0.01ns,那么 1.16ns 则实际上对应 1.16ns 延时。
5.2. `define 和 `undef
`define 用于定义宏。例如,首先定义一个总线宽度的宏为 16,然后利用这个宏定义一个宽度为 16 的 reg 类型数据 Data,方法如下:
1 |
|
在一个文件中出现的 `define,可以被多个文件使用。也就是说 `define 是一种全局的定义。这是 `define 与 parameter 定义的最大区别,在后面也会提到。
`define 指令被编译以后,则在整个编译过程中都有效,直到遇到 `undef 指令,该宏就不再有效。如下:
1 |
遇到该编译指令后,先前的 `define 指令失效。
5.3. `ifdef、`else 和`endif
再来看看如下的条件编译指令:
1 |
|
在这个条件编译指令中,如果先前已经定义了 NARROW 宏,那么参数 BUS_WIDTH 被设置为 16,否则其被设置为 32。`else 指令对于 `ifdef 来说是可选的,也就是说可以单独使用。
5.4. `include
在 Verilog 中,可以使用 `include 指令来嵌入某个文件的内容。例如:
1 |
那么,在编译的时候,就将使用 HEADFILE.h 文件中的内容完全替换这一行语句。而双引号中的文件可以使用相对路径,或绝对路径,或者默认在当前路径以下。
5.5. `resetall
`resetall 编译指令会将所有其他编译指令重新设置为缺省值,要谨慎使用。
Verilog 语言中的编译指令不止这几条,其他不常用的指令这里不一一介绍,有兴趣可以参考其他文献。
6. 逻辑值与常量
6.1. 逻辑值
在二进制计数中,单位逻辑值只有 1 和 0 两种状态。而在 Verilog 语言中,为了对电路进行精确建模,增加了两种逻辑状态 X 和 Z。
X表示未知值(unknown),或者不关心(don’t care),X用作信号状态时表示未知,用在条件判断时(在casex或casez中)表示不关心;Z表示高阻状态,也就是没有任何驱动,通常用来对三态总线进行建模。
在第 7 节将提到 Verilog 语言中的变量类型。通常 net 型变量如果没有初始化,其值为 Z,register 型变量如果没有初始化,其值为 X 。这一点在仿真时显得比较有意义。
但是,对综合工具而言(或者说在实际电路中),并没有什么 X 值,只存在 0、1 和 Z 这 3 种状态。在实际电路中还可能出现亚稳态,它既不是 0,也不是 1,是一种暂时的不稳定状态。
Verilog 语言中所有数据都是由以上描述的 4 种基本的逻辑值 0、1、X 和 Z 构成。同时,X 和 Z 是不区分大小写的。例如:0z1x 和 0Z1X 表示同一个数据。
6.2. 常量
常量是 Verilog 中不变的数值。在上述实例代码中,4'b0001 就表示一个 4 位的二进制整型常量:0001。
Verilog中的常量有3种:
- 整数型;
- 实数型;
- 字符串型。
6.2.1. 整型常量
可以使用简单的十进制表示一个整型常量,例如:
16表示十进制的 16;-15表示十进制的 -15,用二进制补码表示,至少需要 5 位,即 10001,最高一位为符号位;如果用 6 位表示,则是 110001,同样最高一位为符号位。
整数型常量也可以采用基数表示法,例如:
8'haa:表示 8 位的十六进制数,换算成二进制是1010_1010。6'o33:表示 6 位的八进制数,换算成二进制是011_011。4'b1011:表示 4 位的二进制数1011。3'd7:表示 3 位十进制的7。
在基数表示法中,都是以如下格式写的:
1 | [长度]'数值符号 数字 |
其中长度可有可无,数值符号中,h 表示十六进制,o 表示八进制,b 表示二进制,d 表示十进制数据。如果长度比后面数字的实际位数多,则自动在数字的左边补足 0;如果位数少,则自动截断数字左边超出的位数。
如果将数字写成 'haa,那么这个十六进制数的长度就决定于数字本身的长度。
在基数表示法中,如果遇到 X,十六进制数中表示 4 个 X,八进制数中表示 3 个 X。
另外,数字中的下划线没有任何意义,只是增强可读性。例如:4'b1011 和 4'b10_11 一样。
6.2.2. 实数型常量
Verilog 语言中的实数型变量可以采用十进制,也可以采用科学计数法,例如:
1 | 5.512 |
6.2.3. 字符串型常量
字符串是双引号中的字符序列,例如:"Hello World"。字符串是 8 位 ASCII 码值的序列,"Hello World" 就需要 11 字节存储,方法如下:
1 | reg [1:8 * 11] Message; |
这样就将字符串常量存入到 Message 变量中。
7. 变量类型
在 Verilog 语言中,有两大变量类型:
- 线网型:表示电路间的物理连线。
- 寄存器型:Verilog 中的一个抽象的存储数据单元。
对于初学者而言,则需要首先遵守如下的简单规则:
- 凡是在
always或initial语句中赋值的变量,一定是寄存器变量; - 在
assign中赋值的一定是线网变量。
7.1. 线网类型
在线网类型下,分为几种子类,它们具有线网的共性:
wire、tri:表示电路间连线,tri主要用于多驱动源建模;wor、trior:表示该连线具有“线或”功能;wand、triand:表示该连线具有“线与”功能;trireg:表示该连线具有总线保持功能;tri1、tri0:表示当无驱动时,连线状态为 1(tri1)或 0(tri0);supply1、supply0:分别表示电源和地信号。
在以上描述的线网类型中,除了 trireg 未初始化时为 X 以外,其余的未初始化时的值为 Z。
线网类型主要用在连续赋值语句中,以及作为模块之间的互连信号。
在 Part 3——描述方式和设计层次中会详细阐述常用线网类型的使用方法。
7.2. 寄存器类型
寄存器类型变量在 Verilog 语言中通常表示一个存储数据的空间。尤其是在 Verilog 仿真器中,寄存器类型变量通常占据一个仿真内存空间。
reg:是最常用的寄存器类型数,可以是 1 位或者多位,或者是二维数组(存储器);integer:整型数据,存储一个至少 32 位time:时间类型,存储一个至少 64 位的时间值;real,realtime:实数和实数时间寄存器。
7.2.1 reg 类型
寄存器类型数
reg类型可以定位为一个寄存器,可以定义一位或者多位,例如:1
2reg AB; // 定义一个名为 AB 的 1 位寄存器
reg [3:0] ABC; // 定义一个名为 ABC 的 4 位寄存器在多位寄存器中,可以作“位选择”或“部分选择”,例如:
1
2
3ABC [3] = 1; // 将 ABC 的第 3 位赋值为 1
ABC [0] = 0; // 将 ABC 的第 0 位赋为 0
ABC [2:1] = 2'b01; // 将 ABC 的第 1、2 位赋值为 1 和 0这样,整个
ABC变量的值为4'b1010。寄存器类型数组
reg类型可以作为二维数组,也就是存储器,例如:1
reg [3:0] MEMABC [0:7]; // 定义一个存储器,地址为 0~7,每个存储单元是 4 位
与一维的
reg变量不同的是,存储器中的存储单元不能再做位选择或部分选择,而每个单元可以单独赋值。比如:1
MEMABC[1] = 4'b0101; // 为 MEMABC 中的第 1 个存储单元赋值 4'b0101
同时,在 Verilog 中,不存可以对整个存储器赋值的语句,必须对每个单元独立赋值。除非使用
$readmemb或$readmemh系统任务从文件中读入整个或者部分存储器的数据。在 Part 7—— 逻辑验证与 testbench 编写中将讨论如何从文件中读入数据给存储器赋值。
7.2.2. integer 类型
integer 变量通常用于高层次建模,也常用在 for 语句的索引中,例如:
1 | initial |
7.2.3. 其他寄存器类型
另外,time 变量用于存储和处理系统时间,real 和 realtime 用来存储实数和实数时间。
7.3. 变量的物理含义
这里需要引起重视,“线网”变量可以理解为电路模块中的连线,但“寄存器”并不严格对应于电路上的存储单元,包括触发器(flip-flop)或锁存器(latch)。从纯粹语言表达的语义角度来说,寄存器类型变量的值,从一个赋值到下一个赋值被保存下来,并且在仿真过程中会保持而不会丢失。
实际上,从语义上来讲,在 Verilog 仿真工具对语言进行仿真的时候,寄存器类型的变量是占用仿真环境的物理内存的,这与 C 语言中的变量类似。寄存器在被赋值后,便一直保存在内存中,保持该值不变,直到再次对该寄存器变量进行赋值。而线网类型是不占用仿真内存的,它的值是由当前所有驱动该线网的其他变量(可以是寄存器或线网)决定的。这是寄存器和线网最大的区别,也是当初 Verilog 的发明者定义“线网”和“寄存器”变量的根本动机。
在下一小节中,将引入“驱动”和“赋值”两个概念,深入探讨两种变量的含义。
7.4. 驱动和赋值
为了更清楚地描述寄存器和线网变量的概念,将以上述实例代码中的语句来说明。首先,引入 Verilog 语言中两个重要的概念:驱动(Driving)和赋值(Assigning)。
- 线网是被驱动的,该值不被保持,在任意一个仿真步进上都需要重新计算;
- 寄存器是被赋值的,且该值在仿真过程中被保持,直到下一个赋值的出现。
在上述实例代码中,定义了一个 A_xor_wire 的 wire,它是 eq0 和 eq1 相异或的结果。采用如下描述方式:
1 | assign #1 A_xor_wire = eq0 ^ eq1; |
实际上,也可以采用如下的另一种描述方式:
1 | always @(eq0 or eq1) |
当然需要在 module 的声明处,将 A_xor_wire 首先定义成 reg 变量,而不是 wire 变量,即需要做如下定义:
1 | reg A_xor_wire |
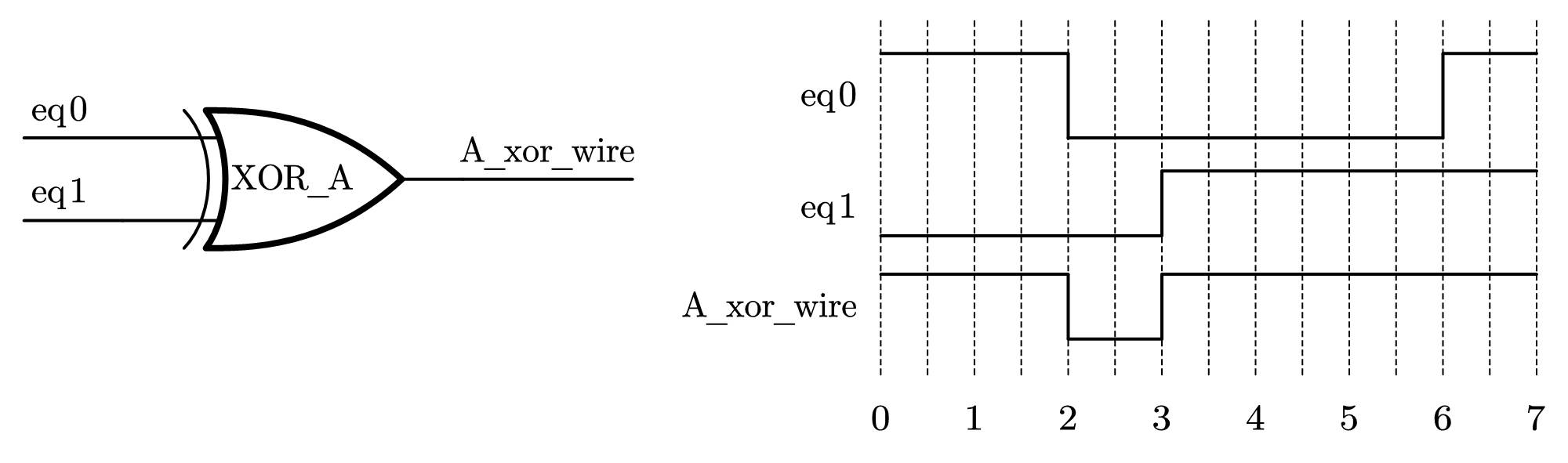
这两者描述的目的一样,都是一个异或门,如图 2-2 所示。
下面从语义上的角度探讨两种描述方式的不同。
第一种描述方式使用 assign 语句,Verilog 中将其称为连续赋值语句(Continuously Assignment),实际上是连续驱动的过程。也就是说,在任意一个仿真时刻,当前时刻 eq0 和 eq1 相异或的结果决定了 1ns 以后(语句 #1 的延时控制)的线网变量 A_xor_wire 的值,不管 eq0 和 eq1 变化与否,这个驱动过程一直存在,因此称为连续驱动。(在仿真器中,线网变量是不占用仿真内存空间的。)如上图 2-2 中的时序所示,这个驱动过程在任意时刻都存在。
在第二种描述方式中使用了 always 语句,后面紧跟着一个敏感列表:@(eq0 or eq1) 因此,这个语句只有在 eq0 或 eq1 发生变化时才会执行。如图 2-2 中,在时刻 2、3 和 6,该语句都将执行,将 eq0 和 eq1 赋值的结果延时 1ns 以后赋值给 A_xor_wire 变量。在其他时刻,A_xor_wire 变量必须保持。因此,从仿真语义上讲,需要一个存储单元,也可以说是寄存器,来保存 A_xor_wire 变量的中间值。这就是 Verilog 语言的“寄存器类型”变量的来历,而这个 A_xor_wire 变量首先需要定义为 reg 类型。
不管采用哪种方式,所描述的是一样的组合逻辑电路。尤其是第二种描述,虽然其在语言中被定义为 reg 型,但并不是对应硬件上的触发器(flip-flop),而是 Verilog 语言仿真语义上的寄存器概念。
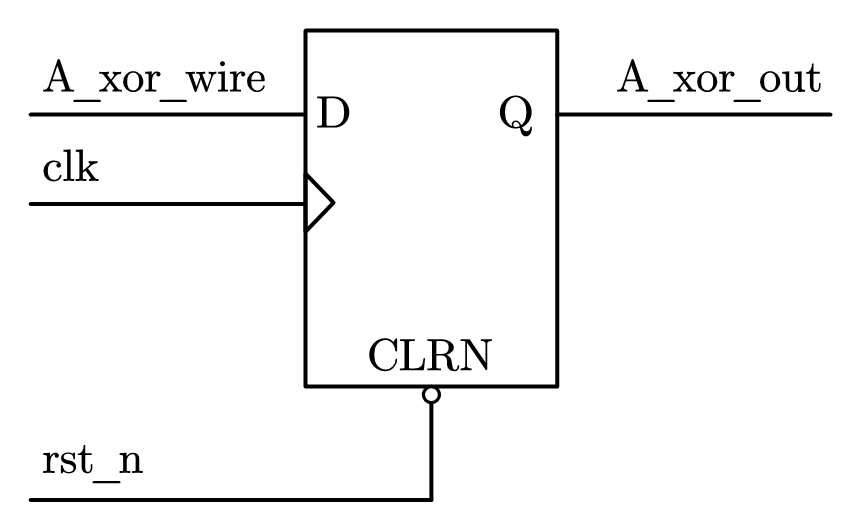
但是,在对实际电路中 D 触发器建模的时候,必须采用 reg 型的变量。图 2-3 是 D 触发器的模型。
在上述实例代码中相应的描述如下:
1 | always @(posedge clk or negedge rst_n) |
D 触发器只对时钟和复位(置位)敏感,因此在敏感列表中,列出了 clk 的上升沿和 rst_n 的下降沿。如果 rst_n 为 0,就对触发器的输出复位,否则在 clk 的时钟上升沿发生的时候,将输入的 A_xor_wire 寄存到触发器的输出端 A_xor_out。
这样的代码精确地描述了一个 D 触发器的行为。这里的 reg 变量就对应了硬件中的 D 触发器。
在叙述时,为了简单起见,常常将“驱动”和“赋值”都统一说成是赋值,但是一定要清楚其中的本质。
8. 参数
参数是一种常量,通常出现在 module 内部。它常常被用作定义状态机的状态、数据位宽和延时大小等等。例如:
1 | parameter and_delay = 2; |
参数的值可以在编译时被改变,因此它又经常被用于一些参数可调的模块中,让用户在实例化模块时,根据需要配置参数。
前面介绍的 `define 是一种全局的定义,而 parameter 是出现在模块内部的局部定义,而且可以被灵活改变,这是 parameter 的一个重要特征。
在 Part 3——描述方式和设计层次的 4.2 参数小节会详细探讨改变模块参数的方法。
9. Verilog 中的并发与顺序
并行概念是硬件中的一个非常重要的概念,特别是初学者或软件工程师们需要重点理解。
与在处理器上运行的软件不同的是,硬件电路之间的工作是并行的。
为了描述硬件的并行性,Verilog 语言本身就具有并发的特性。在 Verilog 语言的 module 中,所有的描述语句(包括连续赋值语句,行为语句块:always 和 initial,模块实例化等)之间都是并行发生的。任何功能描述语句,在 Verilog 的 module 中的顺序都不重要。
但是,在语句块(always 和 initial)内部,则可以存在两种语句组:
begin ... end:顺序语句组;fork ... join:并行语句组。
在 begin ... end 中存在的语句,按照 Verilog 的语义,应该是顺序执行的。而在 fork ... join 中的语句,则是并行执行的。
相比较顺序运行的事物,并行的事物比较难以理解和建模。同时,用于仿真的计算机是串行执行的,而 Verilog 语言本身的语义是用计算机进行模拟的语义,是用一种串行的语义来模拟并行的硬件。
Verilog 仿真器用来模拟硬件的并行行为的方式类似于软件中的多任务操作系统,在某个时刻只能执行一个任务,这样,不同的任务之间看起来是并行执行的。
后续将会重点介绍 Verilog 语言中的这一并行特性,同时阐述 Verilog 的高级仿真原理,希望能帮助大家领会 Verilog 的语义精髓。
10. 操作数、操作符和表达式
10.1. 操作符
操作符是操作数之间的运算符号。在介绍操作数之前,先来看看 Verilog 中的各种操作符。
| 操作符 | 含义 | 操作符 | 含义 |
|---|---|---|---|
+ | 一元加 | >> | 右移 |
- | 一元减 | < | 小于 |
! | 一元逻辑非 | <= | 小于等于 |
~ | 一元按位求反 | > | 大于 |
& | 归约与 | >= | 大于等于 |
~& | 归约与非 | == | 逻辑相等 |
^ | 归约异或 | != | 逻辑不等 |
^~ 或 ~^ | 归约异或非 | === | 全等 |
\| | 归约或 | !== | 非全等 |
~\| | 归约或非 | & | 按位与 |
* | 乘 | ^ | 按位异或 |
/ | 除以 | ^~ 或 ~^ | 按位异或非 |
% | 取模 | \| | 按位或 |
+ | 二元加 | && | 逻辑与 |
- | 二元减 | \|\| | 逻辑或 |
<< | 左移 | ? : | 条件操作符 |
其中,一元操作表示仅有一个操作数,二元操作表示有两个操作数。归约操作也是只有一个操作数,它是该操作数中的所有位之间的计算。
10.1.1. 算术操作符
| 操作符 | 表达式 | 说明 |
|---|---|---|
+ | m + n | 将 n 与 m 相加 |
- | m - n | 将 m 减去 n |
- | -m | 将 m 取反(二进制补码) |
* | m * n | 将 m 与 n 相乘 |
/ | m / n | 将 m 除以 n |
% | m % n | 对 m / n 求模 |
10.1.2. 按位操作符
| 操作符 | 表达式 | 说明 |
|---|---|---|
~ | ~m | 将 m 的每个位取反 |
& | m & n | 将 m 的每个位与 n 的相应位相与 |
| | m | n | 将 m 的每个位与 n 的相应位相或 |
^ | m ^ n | 将 m 的每个位与 n 的相应位相异或 |
~^^~ | m ~^ nm ^~ n | 将 m 的每个位与 n 的相应位相异或非 |
10.1.3. 归约操作符
| 操作符 | 表达式 | 说明 |
|---|---|---|
& | &m | 将 m 中的所有位相与(1位结果) |
~& | ~&m | 将 m 中的所有位相与非(1位结果) |
| | |m | 将 m 中的所有位相或(1位结果) |
~| | ~|m | 将 m 中的所有位或非(1位结果) |
^ | ^m | 将 m 中的所有位异或(1位结果) |
~^^~ | ~^m^~m | 将 m 中的所有位相异或非(1位结果) |
10.1.4. 逻辑操作符
| 操作符 | 表达式 | 说明 |
|---|---|---|
! | !m | m 是否不为真?(1 位 真/假结果) |
&& | m && n | m 和 n 是否都为真?(1位 真/假结果) |
|| | m || n | m 或 n 是否为真?(1位 真/假结果) |
10.1.5. 相等操作符
| 操作符 | 表达式 | 说明 |
|---|---|---|
== | m == n | m 和 n 相等吗?(1 位 正确/错误结果) |
!= | m != n | m 和 n 不等吗?(1 位 正确/错误结果) |
相等操作符仅比较逻辑 1 和 0。
10.1.6. 全等操作符
| 操作符 | 表达式 | 说明 |
|---|---|---|
=== | m === n | m 和 n 全等吗?(1 位 正确/错误结果) |
!== | m !== n | m 和 n 不全等吗?(1 位 正确/错误结果) |
10.1.7. 关系操作符
| 操作符 | 表达式 | 说明 |
|---|---|---|
< | m < n | m 小于 n ?(1 位 正确/错误结果) |
> | m > n | m 大于 n ?(1 位 正确/错误结果) |
<= | m <= n | m 小于等于 n ?(1 位 正确/错误结果) |
>= | m >= n | m 大于等于 n ?(1 位 正确/错误结果) |
10.1.8. 逻辑移位操作符
| 操作符 | 表达式 | 说明 |
|---|---|---|
<< | m << n | 将 m 左移 n 位 |
>> | m >> n | 将 m 右移 n 位 |
10.1.9. 条件操作符
| 操作符 | 表达式 | 说明 |
|---|---|---|
? : | sel ? m : n | 如果 sel 为真,选择 m,否则选择 n |
10.1.10. 连接复制操作符
| 操作符 | 表达式 | 说明 |
|---|---|---|
{ } | {m,n} | 将 m 和 n 连接起来,产生更大的向量 |
{{ }} | {n{m}} | 将 m 重复 n 次 |
在以上描述的操作符之间有优先级之分,下表体现了不同的操作数优先级由高到低排列。
| 操作符 | 优先级 |
|---|---|
!、~、+、-(一元) | 最高优先级 |
*、/、% | \(\vdots\) |
+、-(二元) | \(\vdots\) |
<<、>> | \(\vdots\) |
<、<=、>、>= | \(\vdots\) |
==、!=、===、!== | \(\vdots\) |
&、~& | \(\vdots\) |
^、~^ | \(\vdots\) |
\|、~\| | \(\vdots\) |
&& | \(\vdots\) |
\|\| | \(\vdots\) |
? : | 最低优先级 |
例如:
A + B & C + D就表示(A + B) & (C + D),而不是A + (B & C) + D。
10.2. 二进制数值
在讨论操作数之前,先来看看二进制数中如何表示有符号数和无符号数。
例如,在一个 6 位二进制整形变量中,
- 无符号数能表示的范围是:
0~63; - 有符号数采用二进制补码(Two’s complement)方式,能表示的范围是:
-32~31。其中二进制的最高位表示符号,最高位为 1 表示该数是负数,为 0 表示该数是正数。
这里对具体的编码方式不过多介绍,但学过数字电路的同学必须掌握二进制中无符号数和有符号数的表示方法,以及计算的机制。
10.3. 操作数
在 Verilog 语言中,操作数可以是如下几种:
- 常数;
- 参数;
- 线网;
- 寄存器;
- 向量的位选择;
- 向量的部分选择;
- 存储器单元;
- 系统函数或用户自定义函数调用的返回值。
在选择操作数时,需要用户尤其注意的是操作数的极性。通常在 Verilog 中,无符号数用以下 3 种形式存在:
- 线网变量;
- 一般寄存器变量;
- 基数格式表示形式的整数常数。
而有符号数有:
- 整型寄存器变量;
- 十进制形式的整型常量。
首先讨论常量,如果采用基数格式表示一个数,例如:-4'd12,其二进制表示方式是:1111_1111_1111_1111_1111_1111_1111_0100(1100 的补码),由于基数格式的整数为无符号数,因此-4'd12 的值就是十进制的 429496728。
当采用普通十进制数来表示 -12 的时候,虽然它的二进制表示方式与上面的数相同,但 -12 是一个有符号数,它在运算时就表示十进制的 -12。
这里定义两个变量,一个是无符号的 reg 型,另一个是有符号的整型:
1 | reg [4:0] Opreg; // 一个 5 位的 reg 型,存储无符号数 |
做如下运算:
1 | Opreg = -4d'12/4; // Opreg 被赋值 29,(-4d'12/4) 的最低5位 |
通过以上的计算结果可以看出,无符号数和有符号数的算术运算非常不同,用户在设计常量和变量并用它们计算的时候,一定要搞清楚它们中哪些表示有符号数,哪些表示无符号数,这很重要。
11. 系统任务和系统函数
在 Verilog 语中,预先定义了一些任务和函数,用于完成一些特殊的功能,它们被称为系统任务和系统函数。Verilog 能提供的系统任务和系统函数类型如下:
- 显示任务(display task);
- 文件输入/输出任务(file I/O task);
- 时间标度任务(timescale task);
- 拟控制任务(simulation control task);
- 时序验证任务(timing check task);
- PLA建模任务(PLA modeling task);
- 随机建模任务(stochastic modeling task);
- 实数变换函数(conversion functions for real);
- 概率分布数(probabilistic distribution function)。
由于 Verilog 的系统任务和函数种类很多,在这里,只重点介绍一些常用的内容,希望通过介绍可以能让大家迅速掌握,灵活使用。相信通过以下的介绍,大家可以举一反三,通过参考 Verilog 的语法文献,迅速查找到需要的系统任务和函数,完成需要的功能。
11.1. 显示任务
$display 是显示任务,通常用来显示变量值、字符串,以及仿真时间等信息。
在 HelloVlog 模块中使用了这样的系统任务。
1 | $display ("At time %t-", $time, "eq0 = 1"); // 显示时间 |
其中,双引号中的是字符串,%t 是时间格式。$time 是产生模拟时间的系统函数,它的返回值显示在字符串中的 %t 位置。
再如:
1 | $display("The value of ABC is %d", ABC); // 显示当前 ABC 变量的值 |
其中,%d 表示十进制数。ABC 的值显示在字符串中的 %d 位置。
11.2. 文件输入出任务
系统函数 $fopen 用于打开一个文件,并返回一个整数的文件指针。然后,$fdisplay 就可以使用这个文件指针向文件中写入信息。写完后,则可以使用 $fclose 这个系统关闭这个文件。例如:
1 | integer Write_Out_File; // 定义一个文件指针 |
以上的语法,将 Mpi_addr 和 Data_in 分别显示在 @ %h\n%h 中两个 %h 的位置,写入 Write_Out_File 指针所指的文件 Write_Out_File.txt 中。
用户可以通过 $readmemb 或者 $readmemh 来从文件中读入数据,但是这个文件中的数据格式是一定的。例如:
1 | reg [7:0] DataSource [0:47]; |
就是将 Read_In_FiIe 文件中数据读入到 DataSource 数组中,然后就可以直接使用。
Read_In_File 数据文件的格式,可以参考如下写法:
1 | @2f |
其中,@2f 表示地址,是十六进制;24 表示该地址的数据,以此类推。
11.3. 其他系统任务和数
仿真控制任务
Verilog 中有一些仿真控制任务,例如:
$finish表示使仿真器退出。$stop使仿真挂起。时序验证任务和仿真时间函数
Verilog 仿真器也可以检查设计时序,以及返回当前仿真时间,例如:
$setup系统任务用来检查建立时间。$hold系统任务用来检查保持时间。$time系统函数用来返回一个64位的模拟时间。概率分布函数
$random系统函数可以用来返回一个32位的有符号整型随机数。
需要注意的是,系统任务/函数只可以在 Verilog 仿真器中运行,仅仅对代码仿真有意义,综合和布线工具将忽略所有的系统任务和函数。
除了系统任务和系统函数之外,VeriIog还允许用户自己定义任务和函数。关于自定义的任务和函数的特点及使用方法,请参考后续的相关内容。
参考文献
EDA 先锋工作室. 轻松成为设计高手——Verilog HDL 实用精解. 北京航空航天大学出版社, 2012.