Josh's Note — SystemVerilog 验证
Part 2 数据类型
和 Verilog 相比,SystemVerilog 提供了很多改进了的数据结构。虽然其中的部分结构最初是为设计人员创建的,但对测试人员也同样有用。本文将介绍这些对验证很有用的数据结构。
SystemVerilog 引进了一些新的数据类型,它们具有如下优点:
- 双状态数据类型 (Two-state):性能更好,内存消耗更低。
- 队列、动态数组和关联数组 (Queues, dynamic and associative arrays):内存消耗减少,自带搜索和分类功能。
- 类和结构 (Classes and structures:):支持抽象数据结构。
- 联合和合并结构 (Unions and packed structures):允许对同一数据有多种视图 (view)。
- 字符串 (Strings):支持内建的字符序列。
- 枚举类型 (Enumerated types):方便代码编写、增加可读性。
1. 内建数据类型
Verilog-1995 有两种基本的数据类型:变量 (variable) 和线网 (net)。它们各自都可以有四种取值:0,1,Z 和 X。RTL 代码使用变量来存放组合和时序值。变量可以是:
- 单比特或多比特的无符号数 (unsigned single or multi-bit,
reg [7:0] m); - 32 比特的有符号数 (signed 32-bit variable,
integer); - 64 比特的无符号数 (unsigned 64-bit variable,
time); - 浮点数 (floating point number,
real)。
若干变量可以被一起存放到定宽数组 (fixed-size array) 里。所有的存储都是静态 (static) 的,意味着所有的变量在整个仿真过程当中都是存活 (alive) 的,子程序 (routine) 不能通过堆栈来保存参数和局部变量。线网可以用来连接设计当中的不同部分,例如门原语和模块实例。尽管线网有很多种用法,但是大多数设计者还是使用标量或矢量 wire 来连接各个设计模块的端口。
SystemVerilog 增加了很多新的数据类型,对设计和验证工程师都很有帮助。
1.1. 逻辑 (logic) 类型
在 Verilog 中,初学者经常分不清 reg 和 wire 两者的区别。应该使用哪一个来驱动端口?连接不同模块时又该怎么做?SystemVerilog 对经典的 reg 数据类型进行了改进,使得它除了作为一个变量以外,还可以被连续赋值、门单元和模块所驱动。为了与寄存器类型相区别,这种改进的数据类型称为 logic。任何使用线网的地方均可使用 logic,但要求 logic 不能有多个结构性的驱动,例如在对双向总线建模的时候。此时,需要使用线网类型,例如 wire,SystemVerilog 会对多个数据来源进行解析以后确定最终值。
例 1 给出在 SystemVerilog 中使用 logic 类型的例子。
logic 类型的使用1 | module logic_data_type(input logic rst_h); |
由于 logic 类型只能有一个驱动,所以可以使用它对网表 (netlist) 进行 debug。
- 可以把所有的信号都声明为
logic,如果存在多个驱动,编译时就会出现错误。 - 然而有些信号本来就有多个驱动,例如双向总线,这些信号就需要被定义成线网类型,例如
wire。
1.2. 双状态数据类型
相比四状态数据类型,SystemVerilog 引入的双状态数据类型有利于提高仿真器的性能并减少内存的使用量。最简单的双状态数据类型是 bit,它是无符号的。另四种带符号的双状态数据类型是 byte,shortint,int 和 longint,如例 2 所示。
1 | bit b; // 双状态,单比特 |
虽然使用
byte等数据类型来替代类似logic[7:0]进行声明可以让程序更简洁,但需要注意,这些新的数据类型都是带符号的,所以byte变量的最大值只有 127,而不是 255 (它的范围是 -128~127)。可以使用byte unsigned,但这其实比使用byte [7:0]还要麻烦。在进行随机化时,带符号变量可能会造成意想不到的结果,这一点在后面会讨论到。
在把双状态变量连接到 DUT 务必要小心,尤其是连接到 DUT 的输出时,因为 DUT 产生的
X或Z会被转换成双状态值,而测试代码可能永远也察觉不了。这些值被转换成了0还是1并不重要,重要的是要随时检查未知值的传播。使用$isunknown()操作符,可以在表达式的任意位出现X或Z时返回1,如例 3。
1 | if ($isunknown(iport) == 1) |
使用格式符 %0t 和参数 $time 可以打印出当前的仿真时间,打印的格式在 $timeformat() 子程序中指定。
2. 定宽数组
相比于 Verilog-1995 中的一维定宽数组,SystemVerilog 提供了更加多样的数组类型,功能上也大大增强。
2.1. 定宽数组的声明和初始化
Verilog 要求在声明中必须给出数组的上下界。因为几乎所有数组都使用 0 作为索引下界,所以 SystemVerilog 允许只给出数组宽度的便捷声明方式,跟 C 语言类似。
1 | int lo_hi[0:15]; // 16 个整数 [0]..[15] |
可以通过在变量名后面指定维度的方式来创建多维定宽数组 (multidimensional fixed-size array)。例 5 创建了几个二维的整数数组,大小都是 8 行 4 列,最后一个元素的值被设置为 1。多维数组在 Verilog-2001 中已经引入,但这种紧凑型声明方式却是新的。
1 | int array2 [0:7][0:3]; // 完整的声明 |
如果从一个越界的地址中读取数据,SystemVerilog 将返回数组元素类型的默认值:
- 对于元素为四状态类型的数组,如
logic,返回X; - 对于元素为双状态类型的数组,如
int或bit,返回0。
这适用于所有数组类型,包括定宽数组、动态数组、关联数组和队列,也同时适用于地址中含有 X 或 Z 的情况。线网在没有驱动的时候输出是 Z。
很多 SystemVerilog 仿真器在存放数组元素时使用 32 比特的字 (word) 边界,所以 byte,shortint 和 int 都是存放在一个字中,longint 存放到两个字中。如例 6 所示,在非合并数组中,字的低位用来存放数据,高位不使用。图 1 所示的字节数组 b_unpack 被存放到三个字的空间里。
1 | bit [7:0] b_unpack[3]; // 非合并数组 |

仿真器通常使用两个或两个以上连续的字来存放 logic 和 integer 等四状态类型,这比存放双状态变量多占用一倍的空间。
2.2. 常量数组
例 7 示范了如何使用常量数组,即用一个单引号加大括号来初始化数组 (注意这里的单引号并不同于编译器指引或宏定义中的单引号),可以一次性地为数组的部分或所有元素赋值。在大括号前标上重复次数可以对多个元素重复赋值,还可以为没有显式赋值的元素指定一个默认值。
1 | int ascend[4] = '{0,1,2,3}; // 对 4 个元素进行初始化 |
2.3. 基本的数组操作—— for 和 foreach
操作数组的最常见的方式是使用 for 或 foreach 循环。在例 8 中,i 被声明为 for 循环内的局部变量。SystemVerilog 的 $size 函数返回数组的宽度。在 foreach 循环中,只需要给出数组名并在后面的方括号中给出索引变量,SystemVerilog 便会自动遍历数组中的元素。索引变量将自动声明,并只在循环内有效。
for 和 foreach 循环1 | initial begin |
注意在例 9 中,对多维数组使用 foreach 的语法可能会与设想的有所不同。使用时并不是像 [i][j] 这样把每个下标分别列在不同的方括号里,而是用逗号隔开后放在同一个方括号里,像 [i,j]。
1 | int md[2][3] = '{'{0,1,2}, '{3,4,5}}; |
1 | Initial value: |
如果不需要遍历数组中的所有维度,可以在 foreach 循环里忽略不需要的维度。例 11 把一个二维数组打印成一个方形的阵列。它在外层循环中遍历第一个维度,然后在内层循环中遍历第二个维度。
1 | initial begin |
1 | Initial value: |
最后要补充的是,foreach 循环会按照数组范围的声明方法进行遍历:
- 数组
f[5]等同于f[0:4],foreach(f[i])等同于for(int i=0; i<=4; i++)。 - 数组
rev[6:2],foreach(rev[i])等同于for(int i=6; i>=2; i--)。
2.4. 基本的数组操作——复制和比较
可以在不使用循环的情况下对数组进行聚合比较和复制 (aggregate compare and copy, 聚合操作适用于整个数组而不是单个元素),其中比较只限于等于比较或不等于比较。例 13 列出了几个比较的例子。操作符 ? : 是一个迷你型的 if 语句,在例 13 中用来对两个字符串进行选择。例子最后的比较语句使用了数组的一部分,src[1:4],它实际上产生了一个有四个元素的临时数组。
1 | initial begin |
对数组的算术运算不能使用聚合操作,而应该使用循环,例如加法等运算。对于逻辑运算,例如异或等运算,只能使用循环或合并数组 (packed array)。
2.5. 同时使用位下标和数组下标
在 Verilog-1995 中一个很不方便的地方就是数组下标 (array subscript) 和位下标 (bit subscript) 不能同时使用。Verilog-2001 对定宽数组取消了这个限制。例 14 打印出数组的第一个元素 (二进制 101 )、它的最低位 (1) 以及紧接的高两位 (二进制 10)。
1 | initial begin |
虽然这个变化并不是 SystemVerilog 新增加的,但可能有很多人并不知道 Verilog-2001 中的这个有用的改进。
2.6. 合井数组
对某些数据类型,我们可能希望既可以把它作为一个整体来访问,也可以把它分解成更小的单元。例如,有一个 32 比特的寄存器,有时候希望把它看成四个 8 比特的数据,有时候则希望把它看成单个的无符号数据。SystemVerilog 的合并数组就可以实现这个功能,它既可以用作数组,也可以当成单独的数据。与非合并数组不同的是,它的存放方式是连续的比特集合,中间没有任何闲置的空间。
2.7. 合并数组的例子
声明合并数组时,合并的位和数组大小是数据类型的一部分,必须在变量名前面指定。数组大小定义的格式必须是 [msb:lsb],而不是 [size]。例 15 中的变量 bytes 是一个有 4 个字节的合并数组,使用单独的 32 比特的字来存放,如图 2 所示。
1 | bit [3:0] [7:0] bytes; // 4 个 字节 组装成 32 比特 |

合并和非合并数组可以混合使用。可以使用数组来表示存储单元,这些单元可以按比特、字节或长字的方式进行存取。在例 16 中,barray 是一个具有 3 个合并元素的非合并数组。
1 | bit [3:0] [7:0] barray [3]; // 合并,3×32 比特 |
例 15 中的变量 bytes 是一个具有 4 个字节的合并数组,以单字形式存放。barray 则是一个具有 3 个类似 bytes 元素的数组,其存放形式如图 3。
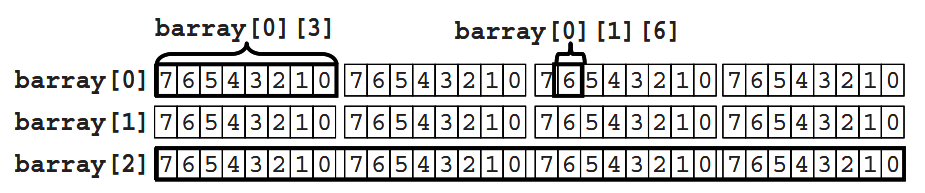
- 使用一个下标,可以得到一个字的数据,如
barray[2]; - 使用两个下标,可以得到一个字节的数据,如
barray[0][3]; - 使用三个下标,可以访问到单个比特位,如
barray[0][1][6]。
注意数组声明中在变量名后面指定了数组的大小,barray[3],这个维度是非合并的,所以在使用该数组时至少要有一个下标。
例 16 中的最后一行在两个合并数组间实现复制。由于操作是以比特为单位进行的,所以即使数组维度不同也可以进行复制。
2.8. 合井数组和非合并数组的选择
应该选择合并数组还是非合并数组呢?当需要和标量进行相互转换时,使用合并数组会非常方便。例如,以字节或字为单位对存储单元进行操作。图 3 中所示的 barray 可以满足这一要求。任何数组类型都可以合并,包括动态数组、队列和关联数组。
如果需要等待数组中的变化,则必须使用合并数组。当 testbench 需要通过存储器数据的变化来唤醒时,需要使用 @ 操作符,但 @ 操作符只能用于标量或者合并数组。在例 16 中,可以把 lw 和 barray[0] 用作敏感信号,但却不能用整个的 barray 数组,除非把它扩展成:@(barray[0] or barray[1] or barray[2])。
3. 动态数组
前面介绍的基本的 Verilog 数组类型都是定宽数组,其宽度在编译时就确定了。但如果直到程序运行之前都还不知道数组的宽度呢?例如,在仿真开始的时候生成一批事件,事件的总量是随机的。如果把这些事件存放到一个定宽数组里,那这个数组的宽度需要大到可以容纳最大的事件量,但实际的事件量可能会远远小于最大值,这就造成了存储空间的浪费。
SystemVerilog 提供了动态数组类型,可以在仿真时分配空间或调整宽度,这样在仿真中就可以使用最小的存储星。
动态数组在声明时使用空的下标 [],表示数组的宽度不在编译时给出,在程序运行时再指定。数组在最开始时是空的,所以必须调用 new[] 操作符来分配空间,同时在方括号中传递数组宽度。可以把数组名传给 new[] 构造符,并把已有数组的值复制到新数组里,如例 17 所示。
1 | int dyn[], d2[]; // 声明动态数组 |
在例 17 中:
- A:调用
new[5]为动态数组dyn分配了 5 个整型元素。 - B:把数组的索引值赋给相应的元素。
- C:把
dyn数组的元素值复制给了另一个数组。 - D:和 E 行显示了数组
dyn和d2是相互独立的。 - F:首先分配了 20 个新元素并把原来的
dyn数组复制给开始的 5 个元素,然后释放 dyn 数组原有的 5 个元素所占用的空间,最终dyn指向了一个具有 20 个元素的数组。 - G:调用
new[]分配了 100 个元素,但并不复制原有的值,原有的 20 个元素随即被释放。 - H:删除了
dyn数组。
调用系统函数 $size 可以返回数组的宽度。动态数组有一些内建的子程序 (routines),例如 delete 和 size。
如果想声明一个常数数组但又不想统计元素的个数,可以使用动态数组并使用常量数组进行赋值。在例 18 中声明的 mask 数组具有 9 个 8 比特元素,SystemVerilog 会自动统计元素的个数,这比声明一个定宽数组然后不小心把宽度错指为 8 要好。
1 | bit [7:0] mask[] = '{8'b0000_0000, 8'b0000_0001, |
基本数据类型相同的定宽数组和动态数组之间可以相互赋值,例如都是 int 时。在元素数目相同的情况下,可以把动态数组的值复制到定宽数组。
当把一个定宽数组复制给一个动态数组时,SystemVerilog 会调用构造函数 new[] 来分配空间并复制数值。
4. 队列
SystemVerilog 引进了一种新的数据类型——队列 (queue),它结合了链表和数组的优点。队列与链表相似,可以在一个队列中的任何地方增加或删除元素,这类操作在性能上的损失比动态数组小得多,因为动态数组需要分配新的数组并复制所有元素的值。队列与数组相似,可以通过索引实现对任一元素的访问,而不需要像链表那样去遍历目标元素之前的所有元素。
队列的声明是使用带有美元符号的下标:[$]。队列元素的编号从 0 到 $。例 19 示范了如何使用方法 (method) 在队列中增加和删除元素。注意队列的常量 (literal) 只有大括号而没有数组常量中开头的单引号。
SystemVerilog 的队列类似于标准模板库 (standard template library) 中的双端队列。通过增加元素来创建队列,SystemVerilog 会分配额外的空间以便新元素能够被快速插入。当元素增加到超过原有空间的容量时,SystemVerilog 会自动分配更多的空间。因此队列可以扩大或缩小,但不用像动态数组那样在性能上付出很大代价,SystemVerilog 会随时记录闲置的空间。注意不要对队列使用构造函数 new[]。
1 | int j = 1, |
还可以使用字下标串联来替代方法。如果把 $ 放在一个范围表达式的左边,那么 $ 将代表最小值,例如 [$:2] 就代表 [0:2]。如果 $ 放在表达式的右边,则代表最大值,如例 20 中初始化块的第一行里的 [1:$] 就表示 [1:2]。
1 | int j = 1, |
队列中的元素是连续存放的,所以在队列的前面或后面存取数据非常方便。无论队列有多大,这种操作所耗费的时间都是一样的。在队列中间增加或删除元素需要对已经存在的数据进行搬移以便腾出空间。相应操作所耗费的时间会随着队列的大小线性增加。
可以把定宽或动态数组的值复制给队列。
5. 关联数组
如果只是偶尔需要创建一个大容量的数组,那么动态数组已经足够好用了,但是如果需要超大容量的呢?假设正在对一个有着几个 G 字节寻址范围的处理器进行建模。在典型的测试中,这个处理器可能只访问了用来存放可执行代码和数据的几百或几千个字节,这种情况下对几 G 字节的存储空间进行分配和初始化显然是浪费的。
SystemVerilog 提供了关联数组 (associative array) 类型,用来保存稀疏矩阵 (sparse matrix) 的元素。这意味着当对一个非常大的地址空间进行寻址时,SystemVerilog 只为实际写入的元素分配空间。在图 4 中,关联数组只保留 0…3、42、1000、4521 和 200,000 等位置上的值。这样,用来存放这些值的空间比有 200,000 个条目的定宽或动态数组所占用的空间要小得多。

仿真器可以采用树或哈希表的形式来存放关联数组,但有一定的额外开销。当保存索引值比较分散的数组时,例如使用 32 位地址或 64 位数据作为索引的数据包,这种额外开销显然是可以接受的。
关联数组采用在方括号中放置数据类型1的形式来进行声明,例如 [int] 或 [Packet]。例 21 示范了关联数组的声明、初始化和遍历过程。
1 | initial begin |
例 21 中的关联数组 assoc 具有稀疏分布的元素:1、2、4、8、16 等等。简单的 for 循环并不能遍历该数组,需要使用 foreach 循环来完成。如果想控制得更好,可以在 do ... while 循环中使用 first 和 next 函数。这些函数可以修改索引参数的值,然后根据数组是否为空返回 0 或 1。
和 Perl 语言中的哈希数组类似,关联数组也可以使用字符串索引进行寻址。例 22 使用字符串索引读取文件,并建立关联数组 switch,以实现从字符串到数字的映射。如例 22 所示,可以使用函数 exists() 来检查元素是否存在。如果试图读取尚未被写入的元素,SystemVerilog 会返回数组类型的默认值,例如对于双状态类型是 0,对于四状态类型是 X。
1 | /* |
6. 链表
System Verilog 提供了链表数据结构,类似于标准模板库 (STL) 的列表容器。这个容器被定义为一个参数化的类,可以根据用户需要存放各种类型的数据。
虽然 SystemVerilog 提供了链表,但应该避免使用它。C++ 程序员也许很熟悉 STL,但是 SystemVerilog 的队列更加高效易用。
7. 数组的方法
SystemVerilog 提供了很多数组的方法,可用于任何一种非合并的数组类型,包括定宽数组、动态数组、队列和关联数组。这些方法有简有繁,简单的如求当前数组的大小,复杂的如对数组进行排序。如果不带参数,则方法中的圆括号可以省略。
7.1. 数组缩减方法
基本的数组缩减方法是把一个数组缩减成一个值,如例 23 所示。最常用的缩减方法是 sum,它对数组中的所有元素求和。这里必须对 SystemVerilog 处理操作位宽的规则十分小心。默认情况下,如果把一个单比特数组的所有元素相加,其和也是单比特的。但如果使用 32 比特的表达式,把结果保存在 32 比特的变量里,与一个 32 比特的变量进行比较,或者使用适当的 with 表达式,SystemVerilog 都会在数组求和的过程中使用 32 比特位宽。
1 | bit on[10]; // 单比特数组 |
其他的数组缩减方法还有 product (积),and (与),or (或) 和 xor (异或)。SystemVerilog 没有提供专门从数组里随机选取一个元素的方法。所以对于定宽数组队列、动态数组和关联数组可以使用 $urandom_range($size (array)-1),而对于队列和动态数组还可以使用 $urandom_ range(array.size()-1)。
如果想从一个关联数组中随机选取一个元素,则需要逐个访问它之前的元素,因为无法直接访问到第 \(N\) 个元素。例 24 示范了如何从一个以整数值作为索引的关联数组中随机选取一个元素。如果数组是以字符串作为索引,只需要将 idx 的类型改为 string 即可。
1 | int aa[int], rand_idx, element, count; |
7.2. 数组定位方法
数组中的最大值是什么?数组中有没有包含某个特定值?要想在非合并数组中查找数据,可以使用数组定位方法。这些方法的返回值通常是一个队列。
例 25 使用一个定宽数组 f[6],一个动态数组 d[] 和一个队列 q[$]。min 和 max 函数能够找出数组中的最小值和最大值。注意,它们返回的是一个队列而非标量。这些方法也适用于关联数组。方法 unique 返回的是在数组中具有唯一值的队列,即排除掉重复的数值。
min、max、unique1 | int aa[int], rand_idx, element, count; |
使用 foreach 循环固然可以实现数组的完全搜索,但是如果使用 SystemVerilog 的定位方法,则只需一个操作便可完成。表达式 with 可以指示 SystemVerilog 如何进行搜索,如例 26 所示。
find1 | int d[] = '{9,1,8,3,4,4}, tq[$]; |
在条件语句 with 中,item 被称为重复参数,它代表了数组中一个单独的元素。item 是默认的名字,也可以指定别的名字,只要在数组方法的参数列表中列出来就可以了,如例 27 所示。
1 | tq = d.find_first with (item==4); // 本例的四个语句都是等价的 |
例 28 示范了几种对数组子集进行求和的方式。第一次求和 (total) 是先把元素值与 7 进行比较,比较表达式返回 1 (为真) 或 0 (为假),然后再把返回结果与对应元素相乘,所以 {9, 0, 8, 0, 0, 0} 的元素和是 17。第二次求和 (total) 则使用条件操作符 ? : 进行计算。
1 | int count, total, d[] = '{9,1,8,3,4,4}; |
当把数组缩减方法与条件语句 with 结合使用时,会产生令人惊讶的结果,例如 sum 方法。在例 28 中,sum 操作符的结果是条件表达式为真的次数。对于例 28 的第一个运算语句来说,总共有两个数组元素大于 7 (9 和 8),所以 count 最后得 2。
返回值为索引的数组定位方法,其返回的队列类型是
int而非integer,例如find_index方法。如果在这些语句中不小心用错了数据类型,那么代码有可能通不过编译。
7.3. 数组的排序
SystemVerilog 有几个可以改变数组中元素顺序的方法。可以对元素进行正排序、逆排序,或是打乱它们的顺序,如例 29 所示。注意,与前述数组定位方法不同的是,排序方法改变了原始数组,而数组定位方法新建了一个队列来保存结果。
1 | int d[] = '{9,1,8,3,4,4}; |
reverse 和 shuffle 方法不能带 with 条件语句,它们的作用范围是整个数组。例 30 示范了如何使用子域对一个结构进行排序。结构和合并结构后面会有解释。
1 | struct packed { byte red, green, blue; } c[]; |
7.4. 使用数组定位方法建立记分板
数组定位方法可以用来建立记分板。例 31 定义了包结构 (Packet),然后建立了一个由包结构队列组成的记分板。后面会解释如何使用 typedef 创建结构。
1 | typedef struct packed |
例 31 中的 check_addr() 函数在记分板里寻找和参数匹配的地址。find_index() 方法返回一个 int 队列。如果该队列为空 (size==0),则说明没有匹配值。如果该队列有一个成员 (size==1),则说明有一个匹配,该匹配元素随后被 check_addr() 函数删除掉。如果该队列有多个成员 (size>1),则说明记分板里有多个包地址和目标值匹配。
对于包信息的存储,更好的方式是采用类 (class),后续会有相关介绍。
8. 选择存储类型
下面介绍基于灵活性、存储器用量、速度和排序要求正确选择存储类型的一些准则。这些准则只是一些经验法则,其结果可能会随着仿真器的不同而不同。
8.1. 灵活性
如果数组的索引是连续的非负整数 0、1、2、3 等,则应该使用定宽或动态数组。当数组的宽度在编译时已经确定时选择定宽数组,如果要等到程序运行时才知道数组宽度的话则选择动态数组。例如,长度可变的数据包使用动态数组存储会很方便。当编写处理数组的子程序时,最好使用动态数组,因为只要在元素类型 (如
int、string等) 匹配的情况下,同一个子程序可以处理不同宽度的数组。同样地,只要元素类型匹配,任意长度的队列都可以传递给子程序。关联数组也可以作为参数传递,而不用考虑数组宽度的问题。相比之下,带定宽数组参数的子程序则只能接受指定宽度的数组。当数组索引不规则时,例如对于由随机数值或地址产生的稀疏分布索引,则应选择关联数组。关联数组也可以用来对基于内容寻址 (content-addressable) 的存储器建模。
对于那些在仿真过程中元素数目变化很大的数组,例如保存预期值的记分板,队列是一个很好的选择。
8.2. 存储器用量
使用双状态类型可以减少仿真时的存储器用量。为了避免浪费空间,应尽量选择 32 比特的整数倍作为数据位宽。仿真器通常会把位宽小于 32 比特的数据存放到 32 比特的字里。例如,对于一个大小为 1024 的字节数组,如果仿真器把每个元素都存成一个 32 比特字,则会浪费 3/4 的存储空间。使用合并数组就有助于节省存储空间。
- 对于具有一千个元素的数组,数组类型的选择对存储器用量的影响不大(除非这种数组的量非常大)
- 对于具有一千到一百万个活动元素的数组,定宽和动态数组具有最高的存储器使用效率。
- 如果需要用到大于一百万个活动元素的数组,那就有必要重新检查一下算法是否有问题。
因为需要额外的指针,队列的存取效率比定宽或动态数组稍差。但是,如果把长度经常变化的数据集存放到动态存储空间里,那么需要手动调用 new[] 来分配和复制内存。这个操作的代价会很高,可能会抵消使用动态存储空间所带来的全部好处。
对兆字节量级的存储器建模应该使用关联数组。注意,因为指针带来的额外开销,关联数组里每个元素所占用的空间可能会比定宽或动态数组占用的空间大好几倍。
8.3. 速度
还应根据每个时钟周期内的存取次数来选择数组类型。对于少量的读写,任何类型都可以使用,因为即使有额外开销,相比整个 DUT 也会显得很小。但是如果数组的操作很频繁,则数组的宽度和类型就会变得很关键。
因为定宽和动态数组都是被存放在连续的存储器空间里,所以访问其中的任何元素耗时都相同,而与数组的大小无关。
队列的读写速度与定宽或动态数组基本相当。队列首尾元素的存取几乎没有任何额外开销,而在队列中间插入或删除元素则需要对很多其他元素进行搬移以便腾出空间。当需要在一个很长的队列里插入新元素时,测试程序可能会变得很慢,这时最好考虑改变新元素的存储方式。
对关联数组进行读写时,仿真器必须在存储器里进行搜索。SystemVerilog 的语言参考手册里并没有阐明这个过程是如何完成的,但最常用的方法是使用哈希表和树型结构。相比其他类型的数组,这要求更多的运算量,所以关联数组的存取速度是最慢的。
8.4. 排序
由于 SystemVerilog 能够对任何类型的一维数组 (定宽、动态、关联数组以及队列) 进行排序,因此应该根据数组中元素增加的频繁程度来选择数组的类型。
- 如果元素是一次性全部加入的话,则选择定宽或动态数组,这样只需对数组进行一次分配。
- 如果元素是逐个加入的话,则选择队列,因为在队列首尾加入元素的效率很高。
- 如果数组的值不连续且彼此互异,例如 {1, 10, 11, 50},那么可以使用关联数组并把元素值本身作为索引。
使用子程序 first、 next 和 prev 可以从数组中查找某个特定值并进而找到它的相邻值。因为链表的是双重链接的,所以可以很容易地同时找到比当前值大的值和小的值。关联数组和链表也都支持对元素的删除操作。相比之下,关联数组通过给定索引的方式来存取元素还是比链表要快得多。
例如,可以使用一个关联数组来存放预期的 32 比特数值。数值生成后便直接写入索引的位优。如果想知道某个数值是否已被写入,可以使用 exists 函数来检查。如果不需要某个元素时,可以使用 delete 把它从关联数组删除。
8.5. 选择最优的数据结构
以下是针对数据结构选择的一些建议:
网络数据包 (Network packets)。特点:长度固定,顺序存取。针对长度固定或可变的数据包可分别采用定宽或动态数组。
保存期望值的记分板 (Scoreboard of expected values)。特点:仿真前长度未知,按值存取,长度经常变化。一般情况下可使用队列,这样方便在仿真期间连续增加和删除元素。如果能够为每个事件给出一个固定的编号,例如 1、2、3……,那么可以把这个编号作为队列的索引。如果事件涉及的全都是随机数值,那么只能把它们压入队列中并从中搜索特定的值。如果记分板有数百个元素,而且需要经常在元素之间进行增删操作,则使用关联数组在速度上可能会快一些。
有序结构 (Sorted structures)。如果数据按照可预见的顺序输出,那么可以使用队列;如果输出顺序不确定,则使用关联数组。如果不用对记分板进行搜索,那么只需要把预期的数值存入信箱 (mailbox)。
对超过百万个条目的特大容量存储器进行建模 (Modeling very large memories, greater than a million entries)。如果不需要用到所有的存储空间,可以使用关联数组实现稀疏存储。如果确实需要用到所有的存储空间,试试有没有其他办法可以减少数据的使用量。如果还有问题,请确保使用的是双状态的 32 比特合并数据。
文件中的命令名或操作码 (Command names or opcodes from a file)。特点:把字符串转换成固定值。从文件中读出字符串,然后使用命令名作为字符串索引在关联数组中查找命令名或操作码。
9. 使用 typedef 创建新的类型
typedef 语句可以用来创建新的类型。例如,要求一个算术逻辑单元 (ALU) 在编译时可配置,以适应 8 比特、 16 比特、 24 比特或 32 比特等不同位宽的操作数。在 Verilog 中,可以为操作数的位宽和类型分别定义一个宏 (macro),如例 32 所示。
1 | // 旧的 Verilog 风格 |
这种情况并没有创建新的类型,而只是在进行文本替换。在 SystemVerilog 中,采用下面的代码可以创建新的类型。本文约定,所有用户自定义类型都带后缀 “_t”。
1 | // 新的 SystemVerilog 风格 |
一般来说,即使数据位宽不匹配,例如值被扩展或截断,SystemVerilog 都允许在这些基本类型之间进行复制而不会给出警告。
注意,可以把 parameter 和 typedef 语句放到一个程序包 (package) 里以使它们能被整个设计和 testbench 所共用。
用户自定义的最有用的类型是双状态的 32 比特的无符号整数。在 testbench 中,很多数值都是正整数,例如字段长度或事件次数,这种情况下如果定义有符号整数就会出问题。把对
uint的定义放到通用定义程序包中,这样就可以在仿真程序的任何地方使用它。
uint 的定义1 | typedef bit [31:0] uint; // 32 比特双状态无符号数 |
对新的数组类型的定义并不是很明显,需要把数组的下标放在新的数组名称中。例 35 创建了一种新的类型,fixed_array5,它是一个有着 5 个元素的定宽数组。例 35 接着声明了一个这种类型的数组并进行了初始化。
1 | typedef int fixed_array5[5]; |
10. 创建用户自定义结构
Verilog 的最大缺陷之一是没有数据结构。在 SystemVerilog 中可以使用 struct 语句创建结构,跟 C 语言类似。但 struct 的功能比类少,所以还不如直接在 testbench 中使用类。就像 Verilog 的模块 (module) 中同时包括数据 (信号) 和代码 (always/initial 代码块及子程序) 一样,类里面也包含数据和程序,以便于调试和重用。struct 只是把数据组织到一起。如果缺少可以操作数据的程序,那么也只是解决了一半的问题。
由于 struct 只是一个数据的集合,所以它是可综合的。如果想在设计代码中对一个复杂的数据类型进行建模,例如像素,可以把它放到 struct 里。结构可以通过模块端口进行传递。而如果想生成带约束的随机数据,那就应该使用类了。
10.1. 使用 struct 创建新类型
可以把若干变量组合到一个结构中。例 36 创建了一个名为 pixel 的结构,它有三个无符号的字节变量,分别代表红、绿和蓝。
pixel 类型1 | struct {bit [7:0] r, g, b;} pixel; |
例 36 中的声明只是创建了一个 pixel 变量。要想在端口和程序中共享它,则必须创建一个新的类型,如例 37 所示。
pixel 结构1 | typedef struct {bit [7:0] r, g, b;} pixel_s; |
在 struct 的声明中使用后缀 “_s” 可以方便用户识别自定义类型,简化代码的共享和重用过程。
10.2. 对结构进行初始化
可以在声明或者过程赋值语句中把多个值赋给一个结构体,就像数组那样。如例 38 所示,赋值时要把数值放到带单引号的大括号中。
struct 类型进行初始化1 | initial begin |
10.3. 创建可容纳不同类型的联合
在硬件中,寄存器里的某些位的含义可能与其他位的值有关。例如,不同的操作码对应的处理器指令格式也不同。带立即操作数的指令,它在操作数位置上存放的是一个常量。整数指令对这个立即数的译码结果会与浮点指令大不相同。例 39 把整数 i 和实数 f 存放在同一位置上。
typedef 创建联合1 | typedef union { int i; real f; } num_u; |
这里使用后缀 “_u” 来表示联合类型。
如果需要以若干不同的格式对同一寄存器进行频繁读写时,联合体相当有用。但是,不要滥用,尤其不要仅仅因为想节约存储空间就使用联合。与结构相比,联合可能可以节省几个字节,但是付出的代价却是必须创建并维护一个更加复杂的数据结构,使用一个带判别变量的简单类可以达到同样的效果。这个判别变量的好处在于它标明了需要处理的数据类型,据此可以对相应字段实施读、写和随机化等操作。假如只需要一个数组,并想使用所有的比特来提高存储效率,那使用合并数组是很合适的。
10.4. 合并结构
SystemVerilog 提供的合并结构允许对数据在存储器中的排布方式有更多的控制。合并结构是以连续比特集的方式存放的,中间没有闲置的空间。例 37 中的 pixel 结构使用了三个数值,所以它占用了三个长字的存储空间,即使它实际只需要三个字节。可以指定把它合并到尽可能小的空间里。
1 | typedef struct packed {bit [7:0] r, g, b;} pixel_p_s; |
当希望减少存储器的使用量或存储器的部分位代表了数值时,可以使用合并结构。例如,可以把若干个比特域合并成一个寄存器,也可以把操作码和操作数合并在一起来包含整个处理器指令。
10.5. 在合井结构和非合并结构之间进行选择
当在合并和非合并结构体间选择时,必须考虑结构通常的使用方式和元素的对齐方式。如果对结构的操作很频繁,例如需要经常对整个结构体进行复制,那么使用合并结构的效率会比较高。但是,如果操作经常是针对结构内的个体成员而非整体,那就应该使用非合并结构。当结构的元素不按字节对齐,或者元素位宽与字节不匹配,又或者元素是处理器的指令字时,使用合并和非合并结构在性能上的差别会更大。对合并结构中尺寸不规则的元素进行读写,需要移位和屏蔽操作,代价很高。
11. 类型转换
SystemVerilog 数据类型的多样性意味着可能需要在它们之间进行转换。如果源变量和目标变量的比特位分布完全相同,例如整数和枚举类型,那它们之间可以直接相互赋值。如果比特位分布不同,例如字节数组和字数组,则需要使用流操作符对比特分布重新安排。
11.1. 静态转换
静态转换操作不对转换值进行检查。如例 41 所示,转换时指定目标类型,并在需要转换的表达式前加上单引号即可。注意,Verilog 对整数和实数类型,或者不同位宽的向量之间进行隐式转换。
1 | int i; |
11.2. 动态转换
动态转换函数 $cast 允许对越界的数值进行检查。相关内容后续对于枚举类型的解释和示例。
11.3. 流操作符
流操作符 << 和 >> 用在赋值表达式的右边,后面带表达式、结构或数组。流操作符用于把其后的数据打包成一个比特流。操作符 >> 把数据从左至右变成流,而 << 则把数据从右至左变成流,如例 42 所示。也可以指定一个片段宽度,把源数据按照这个宽度分段以后再转变成流。不能将比特流结果直接赋给非合并数组,而应该在赋值表达式的左边使用流操作符把比特流拆分到非合并数组中。
1 | initial begin |
也可以使用很多连接符 {} 来完成同样的操作,但是流操作符用起来会更简洁并且易于阅读。
如果需要打包或拆分数组,可以使用流操作符来完成具有不同尺寸元素的数组间的转换。例如,可以将字节数组转换成字数组。对于定宽数组、动态数组和队列都可以这样。例 43 示范了队列之间的转换,这种转换同时也适用于动态数组。数组元素会根据需要自动分配。
1 | initial begin |
数组下标失配是在数组间进行流操作时常见的错误。数组声明中的下标
[256]等同于[0:255]而非[255:0]。由于很多数组使用[high:low](由高到低) 的下标形式进行声明,使用流操作把它们的值赋给带[size]下标形式的数组,会造成元素倒序。同样,如果把声明形式为bit [7:0] src [255:0]的非合并数组使用流操作赋值给声明形式为bit [7:0] [255:0] dst的合并数组,则数值的顺序会被打乱。对于合并的字节数组,正确的声明形式应该是bit [255:0] [7:0] dst。
流操作符也可用来将结构 (例如,ATM 信元) 打包或拆分到字节数组中。在例 44 中使用流操作把结构转换成动态的字节数组,然后字节数组又被反过来转换成结构。
1 | initial begin |
12. 枚举类型
在学会使用枚举类型之前,只能使用文本宏。宏的作用范围太大,而且大多数情况下对于调试者是可见的。枚举创建了一种强大的变量类型,它仅限于一些特定名称的集合,例如指令中的操作码或者状态机中的状态名。例如,使用 ADD、MOVE 或 ROTW 这些名称有利于编写和维护代码,它比直接使用 8'h01 这样的常量或者宏要好得多。定义常量的另一种方法是使用参数。但参数需要对每个数值进行单独的定义,而枚举类型却能够自动为列表中的每个名称分配不同的数值。
最简单的枚举类型声明包含了一个常量名称列表以及一个或多个变量,如例 45 所示。通过这种方式创建的是一个匿名的枚举类型,它只能用于这个例子中声明的变量。
1 | enum {RED, BLUE, GREEN} color; |
创建一个署名的枚举类型有利于声明更多新变量,尤其是当这些变量被用作子程序参数或模块端口时。首先需要创建枚举类型,然后再创建相应的变量。使用内建的 name() 函数,可以得到枚举变量值对应的字符串,如例 46 所示。
1 | // 创建代表 0,1,2 的数据类型 |
这里,使用后缀 “_e” 来表示枚举类型。
12.1. 定义枚举值
枚举值默认为从 0 开始递增的整数。可以定义自己的枚举值。例 47 中使用 INIT 代表默认值 0,DECODE 代表 2,IDLE 代表 3。
1 | typedef enum {INIT, DECODE=2, IDLE} fsmtype_e; |
枚举常量,如例 47 中的 INIT,它们的作用范围规则和变量是一样的。因此,如果在不同的枚举类型中用到了同一个枚举常量名,例如把 INIT 用于不同的状态机中,那么必须在不同的作用域里声明它们,例如模块、程序块、函数和类。
如果没有特别指出,枚举类型会被当成
int类型存储。由于int类型的默认值是 0,所以在给枚举常量赋值时务必小心。在例 48 中position会被初始化为 0,这并不是一个合法的ordinal_e变量。这种情况是语言本身所规定的,而非工具上的缺陷。因此把 0 指定给一个枚举常量可以避免这个错误,如例 49 所示。
1 | typedef enum {FIRST=1, SECOND, THIRD} ordinal_e; |
1 | typedef enum {BAD_O=0, FIRST=1, SECOND, THIRD} ordinal_e; |
12.2. 枚举类型的子程序
SystemVerilog 提供了一些可以遍历枚举类型的函数:
first()返回第一个枚举常赋。last()返回最后一个枚举常量。next()返回下一个枚举常量。next(N)返回以后第 N 个枚举常量。prev()返回前一个枚举变量。prev(N)返回以前第 N 个枚举变量。
当到达枚举常量列表的头或尾时,函数 next 和 prev 会自动以环形方式绕回。
注意,要在 for 循环中使用变量来遍历枚举类型中的所有成员并非易事。可以使用 first 访问第一个成员,使用 next 访问后面的成员。间题在于如何为循环设置终止条 件。如果使用 current! =current.last,则循环会在到达最后一个成员之前终止。如果 使用 current<=current.last,则会造成死循环,因为 next 给出的值永远也不会大于最后一个值。这类似于 for 循环的步长为 0.3,而循环变量定义为 bit [1:0],所以循环永远不会退出。
实际上,可以使用 do ... while 循环来遍历所有值,如例 50 所示。
1 | typedef enum {RED, BLUE, GREEN} color_e; |
12.3. 枚举类型的转换
枚举类型的默认类型为双状态 int。可以使用简单的赋值表达式把枚举变量的值直接赋给非枚举变量如 int。但 SystemVerilog 不允许在没有进行显式类型转换的情况下把整型变量赋给枚举变量。SystemVerilog 要求显式类型转换的原因是可能存在的数值越界情况。
1 | typedef enum {RED, BLUE, GREEN} COLOR_E; |
在例 51 中,$cast 被当成函数进行调用,目的在于把右边的值赋给左边的量。如果赋值成功,$cast() 返回 1。如果因为数值越界而导致赋值失败,则不进行任何赋值,函数返回 0。如果把 cast 当成任务使用并且操作失败,则 SystemVerilog 会打印错误信息。
也可以像例 51 所示的那样使用 type'(val) 进行类型转换,但这种方式并不进行任何类型检查,所以转换结果可能会越界。例如,在例 51 中进行静态类型转换以后,赋给 c2 的值实际上已经越界,所以应该尽量避免使用这种方式。
13. 常量
SystemVerilog 中有好几种类型的常量。Verilog 中创建常量的最典型的方法是使用文本宏 (text macro)。它的好处是:宏具有全局作用范围并且可以用于位段和类型定义。它的缺点同样是因为宏具有全局作用范围,在只需要一个局部常量时可能会引发冲突。此外,宏定义需要使用“`”符号,这样它才能被编译器识别和扩展。
在 SystemVerilog 中,参数可以在程序包里声明,因此可以在多个模块中共同使用。这种方式可以替换掉 Verilog 中很多用来表示常量的宏。可以用 typedef 来替换掉那些单调乏味的宏。其次还可以选择 parameter。Verilog 中的 parameter 并没有严格的类型界定,而且其作用范围仅限于单个模块里。Verilog-2001 增加了带类型的 parameter,但其有限的作用范围仍然使得它无法获得广泛应用。
SystemVerilog 也支持 const 修饰符,允许在变量声明时对其进行初始化,但不能在过程代码中改变其值。
const 变量的声明1 | initial begin |
在例 52 中,colon 的值在 initial 块开头就被初始化。const 还可以作为子程序参数。
14. 字符串
Verilog 中使用 reg 变量来保存字符串,这一表达很不方便。SystemVerilog 中的 string 类型可以用来保存长度可变的字符串。单个字符是 byte 类型。长度为 \(N\) 的字符串中,元素编号从 0 到 \(N — 1\)。注意,跟 C 语言 不一样的是,字符串的结尾并不带标识符 null,所有尝试使用字符 “\0” 的操作都会被忽略。字符串使用动态的存储方式,所以不用担心存储空间会全部用完。
例 53 示范了与字符串相关的几种操作。函数 getc(N) 返回位置 N 上的字节,toupper 返回一个所有字符大写的字符串,tolower 返回一个小写的字符串。大括号 {} 用于串接字符串。任务 putc(M,C) 把字节 c 写到字符串的 M 位上。M 必须介于 0 和 len 所给出的长度之间。函数 substr(start,end) 提取出从位置 start 到 end 之间的所有字符。
1 | string s; |
稍加留意便可发现动态字符串的用处有多大。在别的语言如 C 里,必须不停地创建临时字符串来接收函数返回的结果。在例 53 中,函数 psprintf() 替代了 Verilog-2001 中的函数 sformat()。这个新函数返回一个格式化的临时字符串,并且可以直接传递给其他子程序。这样就可以不用定义新的临时字符串并在格式化语句与函数调用过程中传递这个字符串。
15. 表达式的位宽
在 Verilog 中,表达式的位宽是造成行为不可预知的主要原因之一。例 54 使用四种不同方式实现 1+1:
- 方式 A 使用两个单比特变量,在这种精度下得到
1+1=0。 - 方式 B 由于赋值表达式的左边有一个 8 比特的变量,所以其精度是 8 比特,得到的结果是
1+1=2。 - 方式 C 采用一个哑元常数强迫 SystemVerilog 使用 2 比特精度。
- 方式 D 中,第一个值在转换符的作用下被指定为 2 比特的值,所以结果是
1+1=2。
1 | bit [7:0] b8; |
有一些技巧可以避免这个问题。首先,避免像上例中方式 A 那样由于溢出造成精度受损的情况。也可以使用临时变量,像上例中的 b8 那样,以得到期望的位宽。或者,可以另外加入其他的值去强制获取最小精度,就像上例中的 2'b0。最后,在 SystemVerilog 中,还可以通过对变量进行强制转换以达到期望的精度。
16. 结束语
SystemVerilog 提供了很多新的数据类型和结构,让我们可以在较高的抽象层次上编写testbench,而不用担心比特层次的表示问题。队列很适合用于创建记分板,可以在上面频繁地增加或删除数据。动态数组允许在程序运行时再指定数组宽度,为 testbench 提供了极大的灵活性。关联数组可用于稀疏存储和一些只有单一索引的记分板。枚举类型通过创建具名常量列表,增强代码的可读写性。
但不应该满足于使用这些数据结构来写测试程序。后续讲述的 SystemVerilog 的 OOP 特性将帮我们在更高抽象层次上设计代码,进而提高代码的稳健性和可重用性。
参考文献
- 克里斯·斯皮尔, 斯皮尔, 张春,等. SystemVerilog验证:测试平台编写指南[M]. 科学出版社, 2009.
- Spear C. SystemVerilog for verification: a guide to learning the testbench language features[M]. Springer Science & Business Media, 2008.
也可以采用通配符作为下标进行关联数组的声明,例如
wild[*]。但是不推荐使用这种风格,因为不明确指明数据类型会导致很多问题。一个典型的问题是在foreach循环中——在foreach(wild[j])中的变量j究竟是什么类型?↩︎